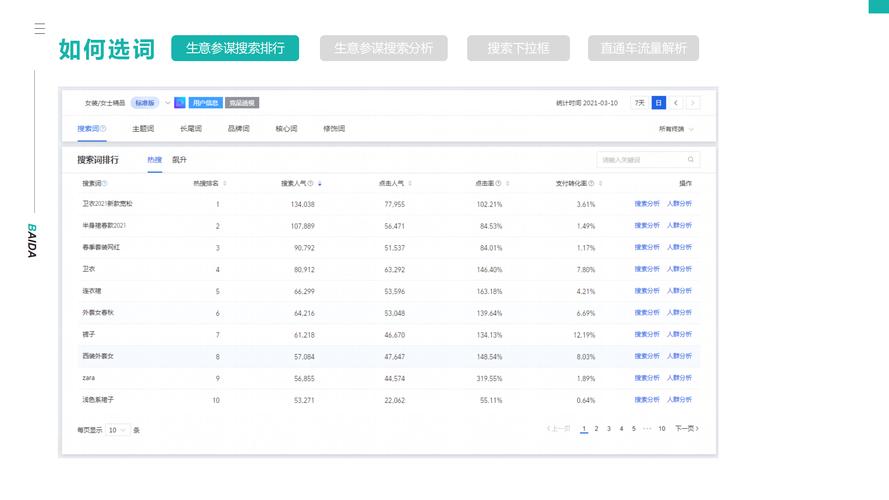
定制数据分析-{下拉词
大家好,今天小编关注到一个比较有意思的话题,就是关于定制数据分析的问题,于是小编就整理了1个相关介绍定制数据分析的解答,让我们一起...


扫一扫用手机浏览
大家好,今天小编关注到一个比较有意思的话题,就是关于r数据分析的问题,于是小编就整理了3个相关介绍r数据分析的解答,让我们一起看看吧。
2/3
3/3
打开微信搜索:ai智能查 点击底部按钮重启查询,把图片输入进去就可以识别得到相应的代码报错故障。
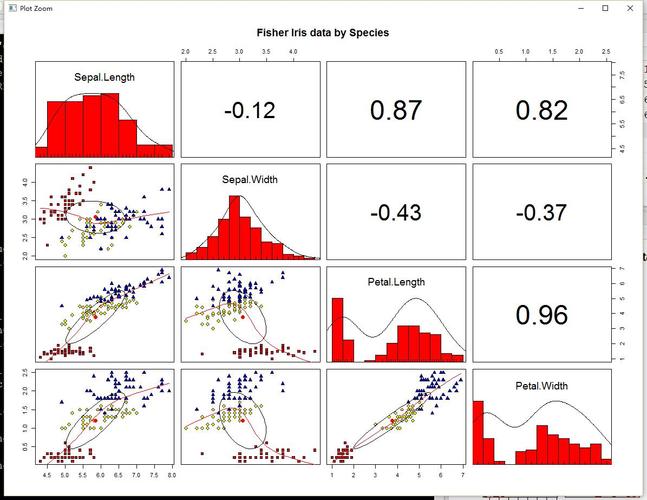
相关系数是最早由统计学家卡尔·皮尔逊设计的统计指标,是研究变量之间线性相关程度的量,一般用字母 r 表示。由于研究对象的不同,相关系数有多种定义方式,较为常用的是皮尔逊相关系数。
相关系数r的绝对值一般在0.8以上,认为A和B有强的相关性。0.3到0.8之间,可以认为有弱的相关性。0.3以下,认为没有相关性。
1、对于网页为csv文件的页面,可以直接用read.csv函数导入网页数据并转为数据框的形式。html格式的网页也可以读取。
例如:
data <- read.csv(text="it is a page")#text是要查看的文本
head(data,10)
#读取网页数据的代码data <- read.csv("page"),page可以是要查看的网址或文本。
2、R基础包中的readLines可以读取网页或文本数据。
#输入文本
cat("asqsd\n1213",file="a1")
readLines("a1") #读取文本数据
#cat中"\n"表示换行。
3、RCurl包中的getURL()函数获取网页数据。
library(RCurl)
data<-getURL("a1")#a1为某个具体的网址。
head(data)
4、通过getURL直接获取的数据有些凌乱,可以借助library(XML)解析树函数htmlTreeParse处理。
library(XML)#解析树函数htmlTreeParse
data_Parse<-htmlTreeParse(data)
head(data_Parse,2)
5、对于复杂网站的文本数据,用rvest包中的read_html函数来提取文本数据。
library(rvest)
page<-read_html("a1")#a1为某个具体的网址
data<-html_nodes(page,"table")
head(data)
#本例中没有输入网址,所以结果为空。
6、通过html_nodes获得的数据不能直接投入使用。
table<-html_table(data);table #提取表格数据,可以得到多个表格结果
table[1]#查看第1个表
text<-html_text(data);text #提取文本数据
#在实际应用中,可以发现提取表格后的数据或文本是非常便于分析的。
1、不管是读取数据还是写入,R都是在工作路径中完成的。所以首先我们要知道我们的R所在的工作路径是在哪里。使用getwd()函数来获取我们的工作路径。
2、下面查看工作路径里面有哪些文件,使用dir()函数。
3、如果你所想导入的数据并不在你当前的工作路径中,有两种方法可以解决。第一种就是把数据文件放到工作路径中,第二种方法就是更改工作路径。更改工作路径使用setwd()函数。比如你想要把工作路径设置成桌面。
4、现在我读取我工作路径中,名字为hw1_data.csv的文件。使用read.csv()函数。
5、也可以使用read.table()函数来读取csv格式的文件。由于csv文件的分隔符是“,”所以我们在用read.table()函数的时候,sep参数,我们要设定为sep=“,”。
6、发现read.table()读出来的数据,列名并不是我们文件中的列名,而是V1,V2。。。我们需要加上header这个参数来修改这个问题。
到此,以上就是小编对于r数据分析的问题就介绍到这了,希望介绍关于r数据分析的3点解答对大家有用。
[免责声明]本文来源于网络,不代表本站立场,如转载内容涉及版权等问题,请联系邮箱:83115484@qq.com,我们会予以删除相关文章,保证您的权利。
大家好,今天小编关注到一个比较有意思的话题,就是关于定制数据分析的问题,于是小编就整理了1个相关介绍定制数据分析的解答,让我们一起...
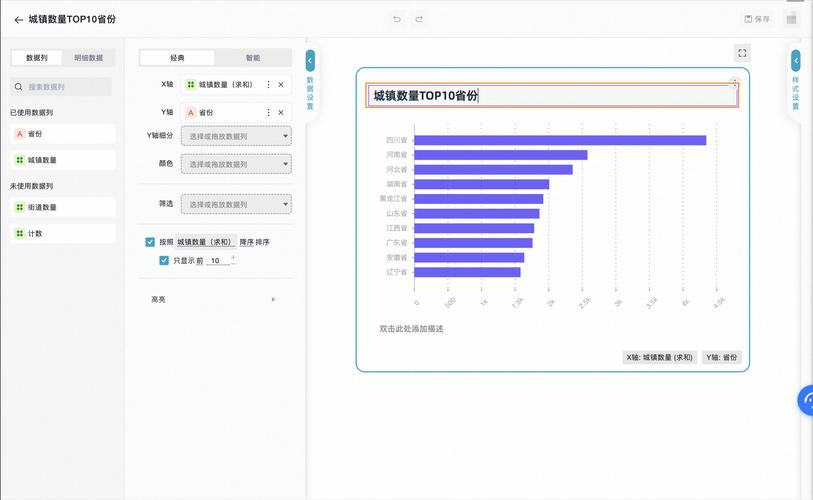
大家好,今天小编关注到一个比较有意思的话题,就是关于大型数据分析的问题,于是小编就整理了5个相关介绍大型数据分析的解答,让我们一起...