


文章目录
[+]
大家好,今天小编关注到一个比较有意思的话题,就是关于hadoop数据分析的问题,于是小编就整理了2个相关介绍hadoop数据分析的解答,让我们一起看看吧。
(图片来源网络,侵删)
定时离线分析hdfs+mapreduce和hadoop+hive+hbase的区别?
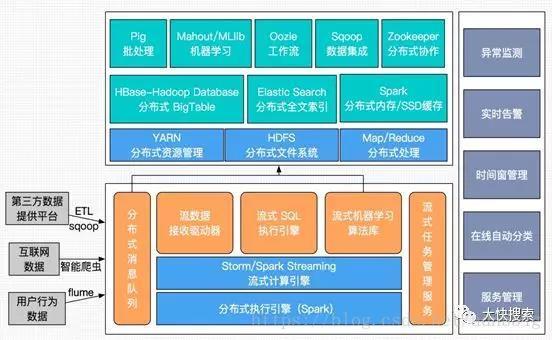
HDFS和MapReduce是Hadoop的两大核心,除此之外Hbase、Hive这两个核心工具也随着Hadoop发展变得越来越重要。
《Thinking in BigDate(八)大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解》从内部机理详细的分析了HDFS、MapReduce、Hbase、Hive的运行机制,从底层到数据管理详细的将Hadoop进行了一个剖析。大数据Spark技术是否可以替代Hadoop?
Spark技术从之前和当前的技术路线上看不是为了替代Hadoop,更多的是作为Hadoop生态圈(广义的Hadoop)中的重要一员来存在和发展的。
首先我们知道Hadoop(狭义的Hadoop)有几个重点技术HDFS、MR(MapReduce), YARN。
这几个技术分别对应分布式文件系统(负责存储), 分布式计算框架(负责计算), 分布式***调度框架(负责***调度)。
我们再来看Spark的技术体系 ,主要分为以下:
- Spark Core :提供核心框架和通用API接口等,如RDD等基础数据结构;
- Spark SQL : 提供结构化数据处理的能力, 分布式的类SQL查询引擎;
- Streaming: 提供流式数据处理能力;
- GraphX : 提供图计算能力
从上面Spark的生态系统看,Spark主要是提供各种数据计算能力的(官方称之为全栈计算框架),本身并不过多涉足存储层和调度层(尽管它自身提供了一个调度器),它的设计是兼容流行的存储层和调度层。也就是说, Spark的存储层不仅可以对接Hadoop HDFS,也可以对接Amazon S2; 调度层不仅可以对接Hadoop YARN也可以对接(Apache Mesos)。
因此,我们可以说Spark更多的是补充Hadoop MR单一批处理计算能力, 而不是完全替代Hadoop的。
【关注ABC(A:人工智能;B:BigData; C: CloudComputing)技术的攻城狮,Age:10+】
回答这个问题之前,首先要搞明白spark和Hadoop各自的定义以及用途,搞明白这个之后这个问题的答案也就出来了。
首先Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
Hadoop是一个由Apache基金***开发的分布式系统基础架构。
Spark是一个计算引擎,主要用来做数据计算用。其核心模块包括Spark Core,Spark Streaming(流式计算),MLlib(集群学习),GraphX(图计算模块)。
Hadoop主要包括HDFS(分布式存储)、MapReduce(并行计算引擎)、Yarn(***调度)。
由此看来,Spark≈MapReduce,同时Spark相比于MapReduce有着更方便的函数处理,在计算速度,开发效率上更有着无法比拟的优势。Spark也支持外部的内存管理组件(Alluxio等),不排除未来Spark也提供分布式文件存储,目前来看没戏。其现在的发展目标主要集中在机器学习这块,已经提供了一体化的机器学习平台。这一点Flink还差点事。目前在国内更多的应用场景是Spark+Hadoop,即使用Spark来做数据计算,用Hadoop的HDFS来做分布式文件存储,用Yarn来做***调度。
到此,以上就是小编对于hadoop数据分析的问题就介绍到这了,希望介绍关于hadoop数据分析的2点解答对大家有用。
[免责声明]本文来源于网络,不代表本站立场,如转载内容涉及版权等问题,请联系邮箱:83115484@qq.com,我们会予以删除相关文章,保证您的权利。
