
教育知识的文章-{下拉词
大家好,今天小编关注到一个比较有意思的话题,就是关于教育知识的文章的问题,于是小编就整理了3个相关介绍教育知识的文章的解答,让我们...


扫一扫用手机浏览
大家好,今天小编关注到一个比较有意思的话题,就是关于机器学习数据分析的问题,于是小编就整理了1个相关介绍机器学习数据分析的解答,让我们一起看看吧。
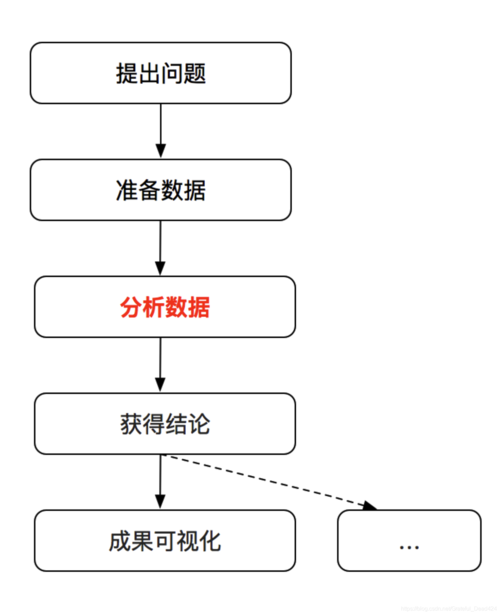
工作后,我首先知道的概念是数据挖掘,而不是机器学习。因此我想数据挖掘这个概念更加广泛,属于工程应用范畴。5年前,我单位谈的都是数据挖掘,也举办这类竞赛,我们也掌握了数据挖掘的应用软件和数据挖掘标准流程,比如sas,clementine等数据挖掘平台。这些平台多数基于图形化操作,应用门槛较低。最近两年才开始谈机器学习,深度学习和人工智能等概念。从我工作经历来讲,数据挖掘是比较大众化的说法,单位业务部门都知道这个概念,而机器学习属于专业化的说法,现在业务部门还不清楚机器学习究竟是什么。其实很难严格去区分两者的关系,看看最权威的数据挖掘和机器学习的教材,你会发现它们大部分都是重复的。既然是两个名称,那么它们的侧重点应该是不一样的。我的理解是数据挖掘的后端与机器学习的前端重复,机器学习的后端与深度学习的前端重复。数据挖掘的前端是数据收集,清洗和处理等,和大数据有关,都涉及数据仓库等内容,但机器学习并不关心这些,也就是说数据这种原材料对机器学习来说应该要事先准备好了,机器学习更加注重学习问题,努力像人类一样学习知识,理解世界。它们最大的区别是:
数据挖掘注重挖掘数据中的规律和知识,但不关心数据为什么会产生这些规律和知识,也就说你只看到表象,并不知道本质原因。而机器学习恰恰相反,机器学习更加注重学习数据的生成机制,即数据究竟由什么概率模型生成的。有时机器学习也叫统计学习就是这个原因。数据的生成机制出来了,那么数据中的规律自然而然就知道了。正是因为机器学习注重数据的生成机制学习,产生大量的研究内容,发展出核机器,极大似然估计,最大熵模型,最大后验估计,期望最大化算法,高斯过程,概率图模型,变分推理等工具。后面这些高级内容,数据挖掘教材一般是没有的。
传统机器学习一般对数据生成机制做一些先验***设,如***设数据由高斯分布生成的,然后学习高斯分布的参数。进一步,如果没有这些***设,应该怎么做?一般使用非参数密度估计技术,如核估计,最近流行和深度学习结合,如生成式对抗网络(GANs),变分自编码器等。
数据挖据和机器学习是处理数据的两个步骤。
首先分析这个问题,要分用户、类别产品类别进行信息***集。并不是所有的淘宝购买信息都要,只要用户的年龄、性别和购买物品的类别以及收藏栏和购物车这些信息。那么这时,用户购买的时间、用户购买时付的费用这些都是无关数据。
这时候就要用到数据挖掘技术了,常用的数据挖据方法是爬虫(这里提醒广大用户,爬虫需要兼顾道德和法律责任,酌情使用)。淘宝自己则不用爬虫,直接运用数据挖掘技术在海量的数据里提取上文说的所需要的信息,这是一个复杂并且漫长的过程。
当所需要的年龄、性别、以及购物类别数据***集完成并分类完成,这时候就需要神经网络来工作了。根据数据分类选择神经网络的种类,并优选网络节点、函数,设定阈值,最后开始训练。最后就得到马云想知道的东西了。
综上所述,数据挖掘侧发现知识,机器学习侧重认识事物,两者相辅相成。
到此,以上就是小编对于机器学习数据分析的问题就介绍到这了,希望介绍关于机器学习数据分析的1点解答对大家有用。
[免责声明]本文来源于网络,不代表本站立场,如转载内容涉及版权等问题,请联系邮箱:83115484@qq.com,我们会予以删除相关文章,保证您的权利。
大家好,今天小编关注到一个比较有意思的话题,就是关于教育知识的文章的问题,于是小编就整理了3个相关介绍教育知识的文章的解答,让我们...

大家好,今天小编关注到一个比较有意思的话题,就是关于数据分析师培训机构课程的问题,于是小编就整理了5个相关介绍数据分析师培训机构课...