
财政大数据分析-{下拉词
大家好,今天小编关注到一个比较有意思的话题,就是关于财政大数据分析的问题,于是小编就整理了3个相关介绍财政大数据分析的解答,让我们...


扫一扫用手机浏览
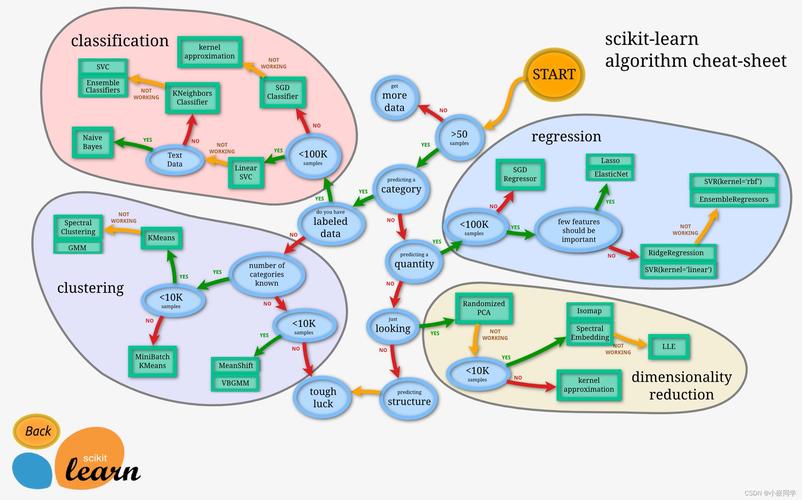
1、特征选择是特征工程的第一步,它直接影响机器学习算法的性能。面对成百上千的特征,如何挑选出最合适的那一部分? 特征来源与选择特征的来源通常有两种:一是通过业务领域专家整理的特征数据;二是从现有特征中通过数据挖掘手段寻找高级特征。
2、特征处理:对数据进行缩放、归一化、标准化、离散化等处理,以便使得机器学习算法更好地处理数据。特征选择:选择最相关的特征,以避免过拟合和提高模型的解释性。选择 特征构造:通过组合、转换、衍生等方式,创造新的特征,以增加数据的表达能力和预测性能。
3、预处理的方法主要包括以下几种:数据清洗、数据转换、数据归一化和特征工程。 数据清洗:在数据预处理阶段,数据清洗是非常重要的一个环节。它主要包括处理缺失值、去除重复数据、处理异常值和噪声等。
4、在机器学习的流程中对模型进行训练和优化是数据收集和准备、特征工程、模型选择和训练、模型评估等。数据收集和准备:在机器学习的流程中,数据收集和准备是第一步。这个阶段主要是对数据进行收集、清洗、预处理等操作,以便后续用于训练模型。
5、特征工程是机器学习中非常关键的步骤。我们要根据不同的知识领域、不同的数据类型和业务目标来构建不同的特征。一般而言,特征工程主要包括:特征提取、特征预处理和特征选择三部分。 特征提取 特征提取是将原始数据转换为有用的特征向量的过程,例如文本特征提取可以将自然语言文本转换为一个有限维向量。
6、选择数据源:用于从外部数据源中导入或加载数据。数据预处理:包括数据清洗、数据变换、缺失值处理等操作。数据探索:用于对数据进行可视化、统计分析、关联分析等操作。特征工程:包括特征选择、特征提取、特征构建等操作,以生成更好的输入特征。
特征选择方法可以分为三类:统计方法、模型方法和集成方法。统计方法,如方差选择、方差分析和相关系数,不依赖于特定模型,仅从特征的角度挖掘其价值,实现特征排序及选择。这些方法易于解释,但可能因阈值选择问题而遗漏有用特征。
综上所述,特征选择是数据分析和机器学习中不可或缺的步骤。通过适当的方法,我们可以从海量特征中筛选出最具有预测能力的特征,从而构建出高效且准确的模型。无论是过滤式、包裹式还是嵌入式特征选择,每种方法都有其适用场景和优势,选择适合具体问题的方法至关重要。
主成分分析方法通过正交变换将数据集转换至具有最大方差值的新数据集中,保留前m个主成分即可保持数据信息量。变换前需对数据进行归一化处理,注意新主成分的解释性。适用于数据解释能力不重要的分析。随机森林方法在组合决策树中用于特征选择和构建分类器。
(1)数据的特征选择 首先要把所有的数据分为回归训练集、回归实验集和回归检验集,根据回归训练集,求出决策函数,再用回归检验集测试所得决策函数的准确率。
相关性分析作为评估特征间关系的工具,有助于揭示数据内在模式和特征间的相互作用。首先,理解特征选择的三种方法:过滤式、包裹式和嵌入式。过滤式通过统计指标独立于算法进行筛选,包裹式则以算法性能评估特征组合,而嵌入式将特征选择与模型训练结合,实现双重优化。
特征选择在实践中具有以下重要性:特征选择方法可以分为三大类:过滤式方法、包裹式方法和嵌入式方法。过滤式方法独立于任何具体的学习算法,通过对特征进行评估和排序来选择特征子集。包裹式方法直接使用学习算法来评估特征子集的性能。
相关性分析在特征选择中扮演关键角色,合理挑选特征,识别与目标变量相关性最高的特征,能快速提升模型效果,实现事半功倍。然而,重要的是理解相关性与因果关系的区别。相关性表示两个变量变化时伴随发生,但不能确认一个原因导致另一个结果,因此相关性不代表因果关系。
由此可见,特征工程尤其是特征选择在机器学习中占有相当重要的地位。
通过比较不同特征的重要性评分,我们可以找出最重要的特征。 使用互信息进行特征选择:互信息是一种衡量两个随机变量之间相关性的方法。在XGBoost中,我们可以计算每个特征与目标变量之间的互信息,总的来说,XGBoost提供了多种方法来进行特征选择,用户可以根据自己的需求和数据的特性选择合适的方法。
1、以Kaggle的***数据集为例,数据包括数值、顺序和分类特征。卡方检验通过交叉表展示数据分布情况,便于分析特征间关系。将性别与***状态进行交叉表分析,结果显示性别与***状态间无显著关系。针对所有分类特征,应用卡方检验,以筛选出与目标变量显著相关的特征。
2、显著性值的选择与样本量有关,通常情况下,样本量较大时,显著性值较小。在机器学习中,特征X与目标Y的数值类型分为连续型和离散型。不同类型的组合适合***用不同的***设检验方法进行相关性分析。T检验是用于比较两组独立样本均值是否显著不同的方法,适用于正态分布且方差齐性的条件。
3、检验两个变量之间的相关性,卡方检验主要被用来检验两个分类变量之间是否存在显著相关性,其结果可以指导我们进行分类变量选择、特征选择、预测和建模等相关工作。此外,通过适当的数据划分和变量转化,卡方检验还可以对两个连续变量之间的相关性进行评估。
4、在实践中,卡方检验广泛应用于频数比较、特征选择和变量关联度分析。但需要注意,它要求观察频数充足,且仅适用于分类数据。卡方分箱算法如ChiMerge,通过初始化和自底向上的合并过程,将连续变量离散化,以优化模型解释性和区分能力,同时结合IV值评估分箱效果。
5、在Toad中,数据探索(EDA)和特征分析是基础。利用toad.detector.detect()功能,可以查看每个特征的类型、分布、缺失率和唯一值。特征选择则通过toad.selection.select()进行,基于缺失率、IV值和相关性进行过滤,如IV小于0.0缺失率大于50%或相关性高于0.7的特征会被剔除。
6、信息增益越大,说明该特征包含的信息量越大,对模型构建越关键。卡方检验作为另一种统计方法,用于评估理论分布与观察数据之间的差异。适用于二分类或多分类问题,其原理是计算观测值与理论分布之间的卡方统计量,通过比较自由度和卡方分布表,评估***设是否成立。
1、规范设计法中比较著名的有新奥尔良(New Orleans)方法。他将数据库设计分为四个阶段:需求分析(分析用户要求)、概念设计(信息分析和定义)、逻辑设计(设计实现)和物理设计(物理数据库设计)。
2、新奥尔良腌料的使用方法包括以下五个步骤:准备食材:准备新奥尔良腌料、鸡翅以及适量的水。调制腌料:将新奥尔良腌料倒入碗中,加入适量的水,充分拌匀,以便用作腌料。处理鸡翅:将鸡翅清洗干净,彻底沥干水分,以备腌制。腌制鸡翅:将处理好的鸡翅放入调好的腌料中,确保每一块鸡翅都均匀裹上腌料。
3、它的使用方法如下:攻击中远程目标:在《战舰世界》游戏中,新奥尔良配备了一组出色的火炮,可以打出较远的射程。因此,可以将其用于攻击中到远距离的目标。依靠队友:新奥尔良是一艘团队支援舰,因此应该与队友一起行动。尽量避免单独行动,以免被敌人集中攻击。
4、食材:新鲜的鸡腿一盘即可,奥尔良腌料一小袋,水少许。将新鲜的鸡腿处理干净,可以在上面划上几道,以便腌制的时候可以更加的入味。把买来的奥尔良腌料倒入小碗中,加入少许的清水,再用筷子将其搅拌均匀。将混合好的奥尔良腌料洒在鸡腿上,再用筷子或手将鸡腿和腌料拌匀。
5、第一步:选择新鲜的翅中或翅根,在表面或背面用针扎几个孔(以方便腌料腌入);洗净。将70g蜜汁烧烤腌料和70***搅拌均匀后倒入1000g翅中或翅根中,混合均匀。(推荐的做法是使用一个结实的口袋,封口,在桌上摔打滚揉,至汁液被肉吸收)。
6、新奥尔良腌料使用方法:调腌料。新奥尔良腌料倒入碗中,加适量水拌匀备用。处理鸡翅。鸡翅洗净,控干水分待用。腌鸡翅。鸡翅放入腌料中抓匀。密封冷藏。鸡翅用保鲜膜密封,冷藏12-24小时。煎鸡翅。热锅烧油,放入鸡翅煎至两面金黄即可。
基于互信息的特征选择方法,选择特征过程简化。子集生成使用前向生成法,评价子集时***用互信息作为准则,停止准则为特征子集达到预设大小。选择特征时,依据互信息大小排序,选取前20个特征,作为特征子集。在选择特征子集时,考虑仅特征与类别的互信息存在局限,可能造成冗余特征。
使用互信息理论进行特征抽取是基于如下***设: 在某个特定类别出现频率高,但在其他类别出现频率比较低的词条与该类的互信息比较大 。通常用互信息作为特征词和类别之问的测度,如果特征词属于该类的话,它们的互信息量最大。
当输入变量间的MI无法区分时,条件MI就显得尤为重要。例如,当[公式]时,选择[公式]还是[公式]取决于[公式]。然而,当样本量不足时,高维联合互信息的估计可能成为问题,需要进一步研究基于参数和非参数密度估计的方法来改进。
方***包括MIFS,MIFS-U,MRMR,NMIFS和MIFS-ND等,这些方法共同特点是通过候选特征与已选择子集内特征的互信息值来计算冗余度,但不考虑类标签。这些方法存在局限性,即忽略了特征间可能共享不同信息于类标签的情况,因此共享信息并不意味着冗余。
[免责声明]本文来源于网络,不代表本站立场,如转载内容涉及版权等问题,请联系邮箱:83115484@qq.com,我们会予以删除相关文章,保证您的权利。
大家好,今天小编关注到一个比较有意思的话题,就是关于财政大数据分析的问题,于是小编就整理了3个相关介绍财政大数据分析的解答,让我们...
大家好,今天小编关注到一个比较有意思的话题,就是关于大数据分析的优势的问题,于是小编就整理了2个相关介绍大数据分析的优势的解答,让...